-
순환 신경망 RNNDeep Learning/밑딥2(자연어 처리) 2021. 7. 23. 22:08728x90
CBOW 모델의 문제점
Tom was watching TV in his room. Mary came into the room. Mary said hi to ?.
문장의 길이가 길면 앞의 단어가 무시될 수 있다.
You say ? and I say hello.
맥락 단어의 순서가 무시된다.
(you, say)와 (say, you)는 행렬곱층을 거쳐 평균을 하면 같은 값이 나온다.
이러한 문제를 해결한 모델이 RNN (Recurrent Neural Network)이다.
RNN
RNN은 순환하는 경로가 있어 데이터가 끊임없이 순환한다.
과거의 정보를 기억하는 동시에 최신 데이터로 갱신한다.
아무리 문장의 길이가 길더라도 맨앞의 단어의 정보를 기억할 수 있다는 뜻이다.

RNN을 시각 단위로 나열하면 아래와같이 풀어쓸 수 있다.

A노드에서 다음 시각으로 정보를 전달하는 동시에 다음 층(h)으로 정보를 전달한다.
그러니까 X0, X1, X2 ... 각각의 값들이 단어 하나 하나에 해당한다.
활성화 함수
RNN에서는 활성화 함수를 tanh를 쓴다.
수식과 그래프는 아래와 같다.


tanh의 도함수는 아래와같다.

계산 그래프

순전파
h_prev (전 시각에서의 출력값), x(입력 데이터) 두 데이터가 입력된다.
각각의 가중치 W_h, W_x 를 행렬곱하기 하고 두 값을 합한 뒤 편향까지 더한다.
활성화함수 tanh를 적용하여 다음 시각과 다음 층으로 전달한다.
역전파
tanh의 역전파는 아래와같다.

나머지 역전파는 MatMul노드, repeat노드, +노드 이므로 생략
RNNLM
RNN의 Language Model 의 형태는 아래와같이 생겨먹었다.
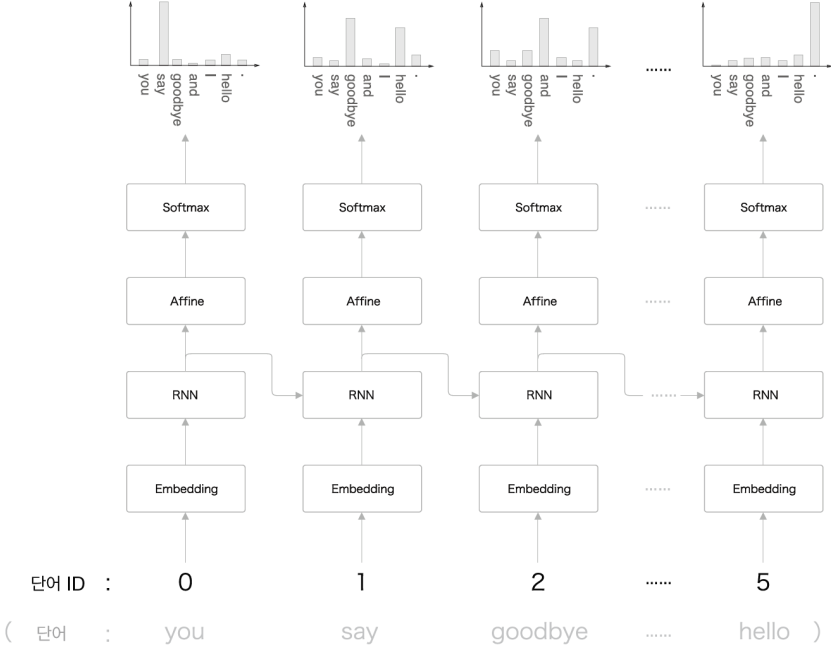
Embedding층 RNN층 Affine층 Softmax층으로 이루어져 있다.
Embedding층에서 입력단어에 해당하는 Weight Matrix를 슬라이싱한다.
RNN층에서 다음 층과 다음 시각으로 정보를 흘려주고
Affine 변환을 한 다음 Softmax층에서 확률로 바꾸어 준다.
입력은 단어의 ID이고 정답 레이블은 입력 단어의 다음 단어의 ID가 된다.
Truncated Back Propagation Through Time
시계열 데이터의 처음부터 끝까지 순전파를 하고 다시 끝 지점에서 역전파를 하면 시간이 매우 오래걸린다.
그래서 Truncated Back Propagation Through Time 를 적용하여 계산한다.
줄여서 Truncated BPTT 라고 부른다.
Truncated BPTT
말뭉치를 일정한 길이의 블록으로 나눈다.
순전파는 처음부터 끝까지 이어지고 역전파만 나눈다.

첫번째 블록에서 순전파를 하고 다시 첫번째 블록의 끝에서 처음까지 역전파를 한다.
첫번째 블록의 동일한 가중치 행렬에서 gradient를 모두 구하고 합한 후 가중치 행렬을 업데이트한다.
업데이트 된 가중치 행렬이 두번째 가중치 행렬이 된다.
두번째 블록에서도 마찬가지로 순전파, 역전파를 한뒤
동일한 가중치 행렬에서 gradient를 머두 구하고 합한 후 가중치 행렬을 업데이트한다.
이런 식이다.
미니 배치
미니 배치를 고려한 학습 처리 순서이다.
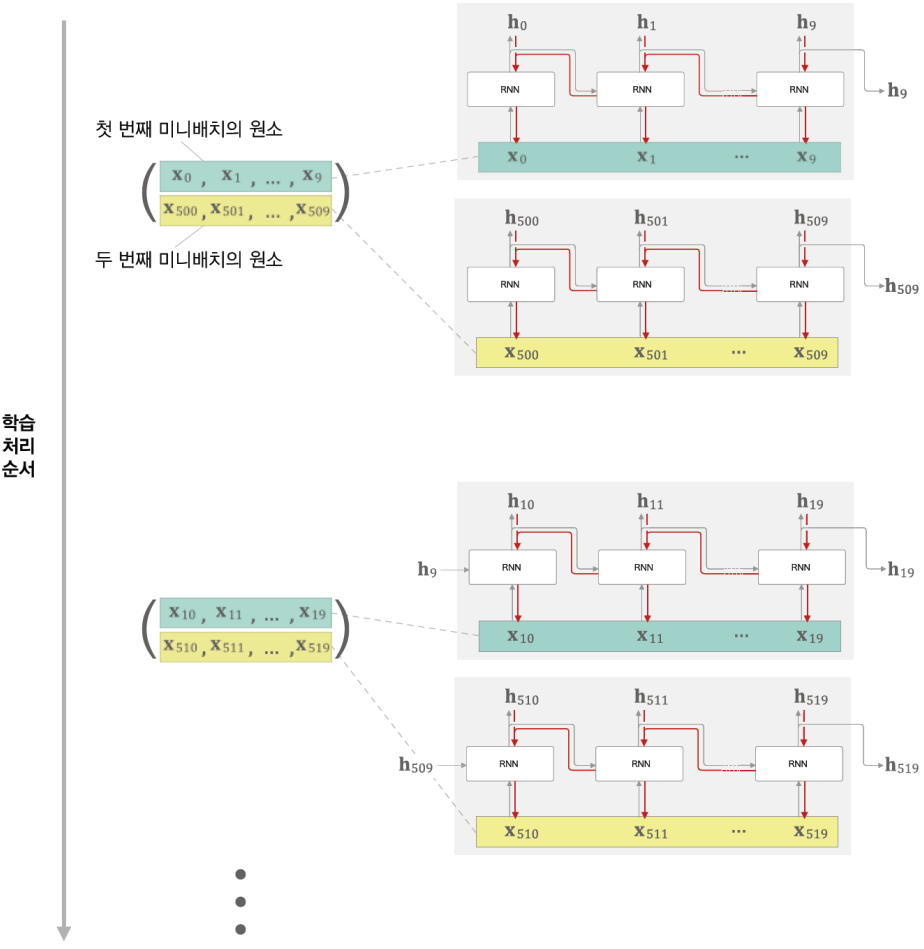
이런식으로 처리하면 시계열 데이터의 순서가 섞이지 않나라는 의문이 들었다.
찾아보니 어쩔 수 없는 문제라고 한다. 화가 난다.
PTB 데이터 변환
PTB 데이터는 자연어 처리의 MNIST 같은거라고 보면 된다.
아래와 같은 말뭉치가 있다. (단어를 ID로 변환함)

size = 1000 batchsize를 10으로 정하여 10등분 한다. (각 행에 써준다.)
Truncated BPTT를 고려해 time_size 5로 정하여 나눈다.

가로 길이가 99이다. 100 아닌가?
입력 데이터는 마지막을 제외시킨 1000 - 1 = 999 개의 데이터만 입력한다.
마지막 단어를 예측하기 위해서는 999개의 단어만 필요로 한다.
999개의 단어를 batch size 10 으로 정수 나누기를 하면 999 // 10 = 99
마지막 9개의 단어가 남는데 이 9개의 단어는 다음 epoch에서 학습한다.
Perplexity
자연어 처리에서는 모델의 성능을 perplexity = exp(cross entropy) 로 평가한다.
값이 낮을수록 성능이 좋다고 여긴다.
이 값의 의미는 선택사항의 수이다.
예를들어 10이 나왔다면 정답의 후보가 10개라는 것이다.
신경망이 정답에 대한 확률을 1/N이라고 예측했다면 perplexity는

이다.

이미지 출쳐 : http://colah.github.io/posts/2015-08-Understanding-LSTMs/
https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
https://deepmind.com/blog/article/decoupled-neural-networks-using-synthetic-gradients
728x90'Deep Learning > 밑딥2(자연어 처리)' 카테고리의 다른 글
추론 기반 기법 (0) 2021.07.16 자연어와 단어의 분산 표현 (0) 2021.07.16